note
- 容错推送工具的设计
- 潜在bug以及问题的处理
背景
目前gamebar有4亿个kv数据需要同步到新的数据库,项目组希望能尽快完成数据的导入,并且保证数据的完整性和正确,实时数据已经通过流水实时同步到新的数据库,此工具是完成历史数据的导入,对于更新时间戳新于历史数据的不予同步,如此可保证数据的正确性和完整性
一个不好的开始
以上是这个需求的背景,但是实际上之前春节的时候,我就做过一个类似的push工具,只不过当时的与我对接的服务端是 手Q公众号 和 手Q红点系统,这都是久经考验的后台系统,成功率几乎就是100%,延迟也非常低,也允许udp协议访问,最重要的是推送量很小,不足一亿,其实有了这几个条件,推送工具就非常好写了,我当时都没写出错处理,也没考虑负载啥的,直接怼了几百个微线程开始发包,结果也没啥问题。后来又有了类似的推送工具的需求,但是客观条件不是很好,推送延迟高(100MS),成功率低(qps超过4000后甚至彻底不可用),只支持tcp访问,数据量非常大(4E kv),我当时的第一版尝试是直接用以前的方法,100个工作线程先怼上去,结果就非常不符合预期,推送QPS低的我想骂人,因为单次推送延迟大,推送QPS就很难上去,那再加100个微线程,然后我的机器就高负载了,最终我只能把推送线程放到150个,我以为这样终于就没问题了,我吃完了饭回来一看运行log, error log就像疯了一样刷屏。
我需要怎么做
至此我开始思考一些问题,我的系统无法继续工作了,我需要怎么知道这件事情?我的系统要怎么做到自动从错误中恢复?如果我的系统彻底崩了,那我再次手动重启的时候,我的系统怎么知道上次的工作进度?当然还有更重要的,我的系统需要能从上次挂掉的地方继续工作(从头再来这种体验真的太差了),4E kv的推送肯定不可能完全不出错,我的系统怎么保证最终成功率,还有一点就是,当出现后端错误的时候,后端接下来继续出错的概率应该是非常高的,我的系统在此时应该能智能调速,当后端服务彻底不可用时,我的推送工具应该要停止工作—>自动保存事故现场—>短信或者微信通知到我。 预感以后这种推送任务会比较多, 需要设计一种独立于业务的框架。
初步的设计
关键数据结构
1 | struct CallerInfo |
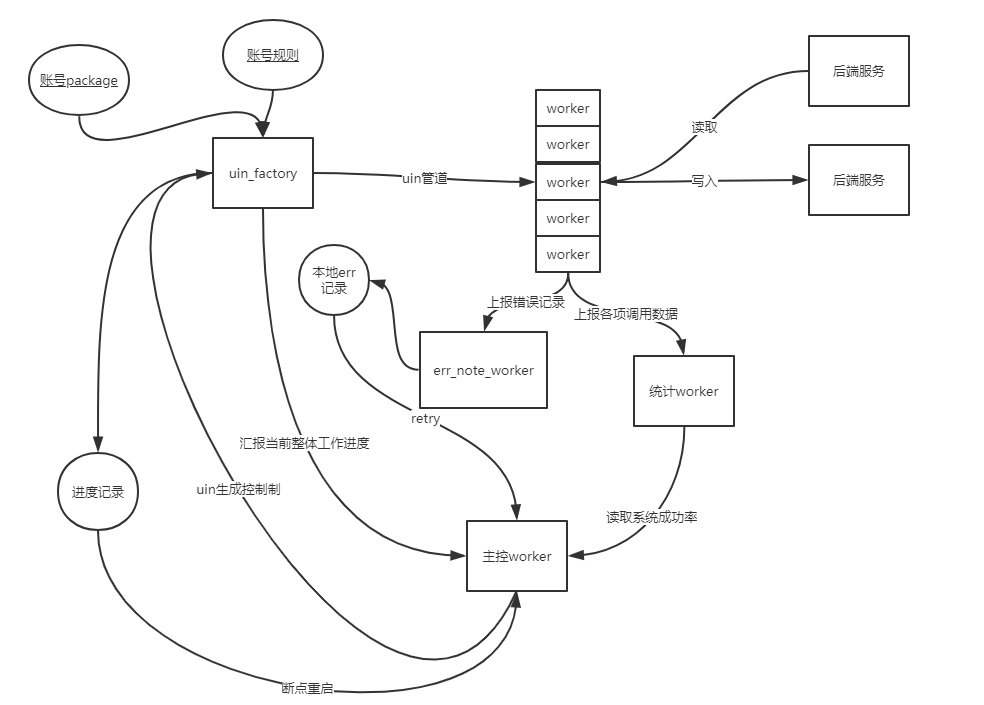
容错
目前针对推送client还没有统一的框架,也即数据上报,容错处理都需要自己写代码完成
这里主要涉及几个方面
- 系统运行情况的上报
- 与svr交互情况的上报 (callerIp , calleeIp:port , delay )
- 处理进度的实时落盘记录
- 出错推送的记录
- 重启后能继续上次的进度继续完成任务
数据上报的内容
- 对于这种小工具,全面的监控也是必须的,一趟处理必有几个关键点,这几个关键点是成功还是失败,如果失败了,是哪种失败,这种数据都要上报,在系统的测试阶段,这些数据也是很方便分析bug
- 对于关键性的操作, 系统需要记录其累计次数, 总共的处理数, 总共的失败次数, 当前分析周期内从成功数, 失败数, 处理数 , 系统负载各项指标
- 对于失败的处理, 需要记录一个能唯一标识此次处理的id, 方便之后统一retry
- 对于成功处理过的, 需要记录下来, 保证系统意外重启后能成功跳过这些.
数据上报的实行
- 数据上报的优先级高于处理, 没有上报就不能进行推送
- 有单独的microThread来处理这些上报,不要阻塞主线程,异步上报
系统的重启与保护
- 偶发的进程挂掉或者严重的系统错误对于这种工具来说是灾难性的,这点一定要在考虑范围内
- 对于极度严重的错误, 系统留下现场后就可以直接退出了,然后自动发wechat消息通知管理员
- 无异常情况下需要定时检查任务是否还在执行, 如果发现进程已不在, 尝试自动拉起进程, 失败多次仍不可成功, 自动 wechat 通知
- 服务端的情况不是client可以控制的, 我们通过成功率和延时来自动调节client的请求速度, 当成功率高, 延时低的时候加快速度请求, 当出现一例失败后, 按 -x% 减少qps , 比如 A 的成功率, 则推送速度的减少不可大于 k * (1 – A) , 这是为了防止qps不断减少导致推送任务不可进行,有时候减小速度可以提高成功率, 但有时候成功率和请求速度没有很大的相关性。
- 推送工具因意外情况重启后,第一步是检查processed文件, 跳过已经处理过的文件和block
遇到的问题
按理这种高io的推送工具cpu应该非常低才对,即使并发量上去了,cpu也不会非常高,但是实际上我在推送微线程到达50个的时候,系统负载就开始剧烈波动
- 50 microThread主推送, 每个microThread的网络请求会阻塞这个microThread
- 一次DoRequest 的延时 10ms 左右
- 单线程从文件读取id, push进任务队列, 50消费线程从任务队列中取出任务进行推送
- cpu 在50 %—600%之间循环跳变
- qps时高时低,稳定抖动
- tcpdump 抓包发现大量fin包, 且都是我方先发的这种包(推送任务调的的tcp的接口)
- perf 观察到60%的cpu时间消耗在port的寻找(kerner)和connection_establish中的spin_lock上了
初步的分析
- 接口在每次发完请求后就断开了链接,大量的先发fin包可以验证这一点
- 并发的connect容易造成竞争, 从perf的结果也可以看出, maybe connect的发起应该有单线程完成, 后续处理教给业务线程
- 对于tcp服务, 要应用连接池