kafka consumer的实践
下午无聊试了下用go写一个kafka consumer,发现效果非常好,而且方便测量性能,赶紧记录下数据
kafkaServer 参数
1 | 网络类型:内网 |
空载时的消费能力
1 | consumer数量:1 |
通过以上数据可以得出,client拉取数据的速度是非常快的,这基本不会成为消费能力的瓶颈,其平均delay不到 10 us。而我们的业务处理,基本是ms级别了,远远落后于pull 的速度,所以把 pull 和 process 放在一条执行路径上是非常愚蠢的,将极大的阻塞消费速度。
我记得之前第一次用kafka的时候,还是用c++写的client,当时的就是把 pull 和 process 放在一个线程中,其消费能力低得惨不忍睹,后来开始一次pull 20条消息后处理,但是还是没有把 process 和 pull 分离,但是消费速度还是有很大的提升。这里的瓶颈其实就是process阻塞了 pull,而通过起大量物理线程来提高速度的方法也不可取,第一consumer的数量受制于partition数量,第二 物理线程对机器负载消耗非常高,总之物理线程太贵了。
process时间大部分都花在网络等待上了,应该把这一过程异步化,或者微线程化(这两种本质一样),我们需要两样东西,pull unit与 process unit通信的管道,好用的微线程框架 / 异步框架。其实在c++里面,以上两点基本就不用考虑了,没那么多好用的轮子给你用,写个业务代码还要自己造轮子,肯定是完成不了任务的。如果这个时候用golang,那么以上两样东西就是语言自带的特性,非常棒。
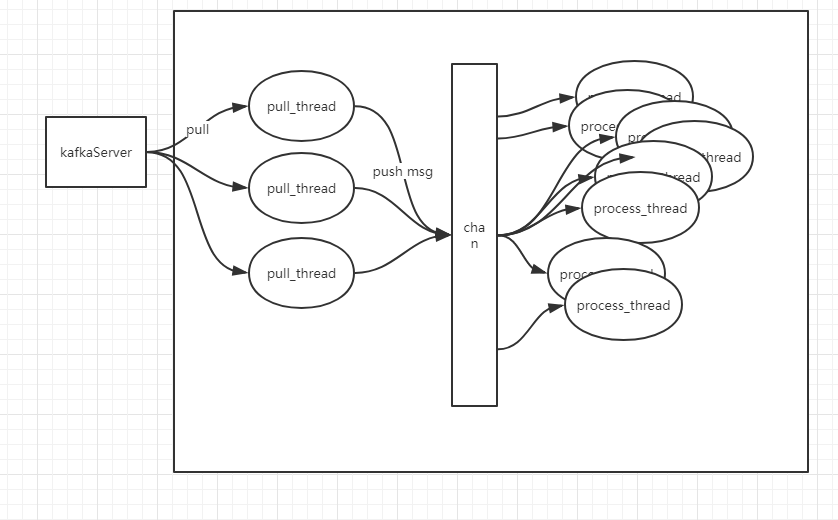
在go里面 微线程是非常廉价的,一个pull thread可以对接很多个processThread,这可以通过配置文件来控制,如果发现速度还是不够OK,可以增加pull thead的数量,一般来说,只有process_thread的处理速度超过单个pull thead的拉取速度的时候才适合增加pull thread。
几个例子
1 | process time : 20 ms (通过time.sleep实现) |
| process time | process thread | pull thread | 消费速度 /s | cpu |
|---|---|---|---|---|
| 20 ms | 10 | 1 | 500 | 3% |
| 20 ms | 20 | 1 | 1000 | 4.5% |
| 20 ms | 40 | 1 | 2000 | 6% |
| 100ms | 40 | 1 | 400 | 4% |
| 100ms | 80 | 1 | 800 | 4% |
可以看到消费能力几乎就是与 处理微线程的数量成正比,而且cpu消耗也没有特别多,起码在低速情况下,直接增加process 微线程的数量,就能直接获得消费性能的提升